Evaluating Denoising Efficiency¶
Introduction¶
This notebook demonstrates how the simulated image quality phantoms generated in the first demo notebook can be used to evaluate pediatric generalizability of CT denoising models. Pediatric generalizability refers to how well a model performs across pediatric subgroups, please see Nelson et al., 2023 for more.
Subgroup |
Age Range |
Waist Diameter Range |
|---|---|---|
Newborn |
≤ 1 mo |
≤ 11.5 cm |
Infant |
> 1 mo & < 2 yrs |
> 11.5 cm & ≤ 16.8 cm |
Child |
> 2 yrs & ≤ 12 yrs |
> 16.8 cm & ≤ 23.2 cm |
Adolescent |
> 12 yrs & < 21 yrs |
> 23.2 cm & < 34 cm |
Adult |
≥ 22 yrs |
≥ 34 cm |
Pediatric subgroups investigated defined by age range (Source: Guidance on Premarket Assessment of Pediatric Medical Devices) with representative effective waist diameters (AAPM Task Group 220). level
Noise Reduction in Uniform Phantoms¶
This notebook focuses on how to use the uniform water phantom (similar to the CTP486 module of the Catphan 600 phantom) to evaluate noise reduction efficiency.
Here noise is defined as local pixel standard deviation \(\sigma\) in a uniform region:
We can thus define noise reduction relative to the input FBP image as:
For the purposes of demonstration, this notebook compares a pretrained deep learning denoising model based on a RED-CNN architecture to compare against a baseline FBP image series. To do this a few more libraries need to be installed to load and run the model (Torchvision) and to visualize the results (Matplotlib and Seaborn)
[1]:
!pip install torchvision -q
!pip install seaborn -q
!pip install matplotlib -q
The following cell loads the necesarry libraries and downloads the pregenerated dataset from Zenodo. Note, you can replace the value of base_dir with the path of your simulation results from the first demo notebook or from running the command line function, so long as the path contains the metadata.csv file
which containing the file paths and file metadata summaries.
[2]:
from pathlib import Path
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import pandas as pd
import pydicom
from torchvision.datasets.utils import download_and_extract_archive
base_dir = Path('data')
if not base_dir.exists():
url ='https://zenodo.org/records/11267694/files/pediatricIQphantoms.zip'
download_and_extract_archive(url, download_root=base_dir)
base_dir = base_dir / 'pediatricIQphantoms'
One important detail when loading metadata.csv is that file paths under the file column are relative which means the dataset can be moved without breaking file paths. However, some functions require absolute file paths, these can be added usins the apply method on the dataframe column (3rd line in the cell below and copied here for reference):
meta.file = meta.file.apply(lambda o: base_dir.absolute() / o)
[3]:
meta = pd.read_csv(base_dir / 'metadata.csv')
meta = meta[meta.phantom == 'uniform']
meta.file = meta.file.apply(lambda o: base_dir.absolute() / o)
meta.head()
[3]:
| Name | effective diameter [cm] | age [year] | pediatric subgroup | phantom | scanner | Dose [%] | recon | kernel | FOV [cm] | file | patientid | studyid | series | repeat | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3544 | 11.2 cm uniform | 11.2 | 0.083333 | newborn | uniform | Siemens Somatom Definition | 25.0 | fbp | D45 | 12.0 | /home/brandon.nelson/Dev/Regulatory_Science_To... | 16.0 | 64 | simulation | 0 |
| 3545 | 11.2 cm uniform | 11.2 | 0.083333 | newborn | uniform | Siemens Somatom Definition | 25.0 | fbp | D45 | 12.0 | /home/brandon.nelson/Dev/Regulatory_Science_To... | 16.0 | 64 | simulation | 1 |
| 3546 | 11.2 cm uniform | 11.2 | 0.083333 | newborn | uniform | Siemens Somatom Definition | 25.0 | fbp | D45 | 12.0 | /home/brandon.nelson/Dev/Regulatory_Science_To... | 16.0 | 64 | simulation | 2 |
| 3547 | 11.2 cm uniform | 11.2 | 0.083333 | newborn | uniform | Siemens Somatom Definition | 25.0 | fbp | D45 | 12.0 | /home/brandon.nelson/Dev/Regulatory_Science_To... | 16.0 | 64 | simulation | 3 |
| 3548 | 11.2 cm uniform | 11.2 | 0.083333 | newborn | uniform | Siemens Somatom Definition | 25.0 | fbp | D45 | 12.0 | /home/brandon.nelson/Dev/Regulatory_Science_To... | 16.0 | 64 | simulation | 4 |
[4]:
sorted(meta['FOV [cm]'].unique())
[4]:
[12.0, 14.0, 17.0, 20.0, 24.0, 32.0, 34.0, 39.0]
The notebook utils folder contains a couple of useful visualization functions, browse_functions for static image viewing and study_viewer provides an interactive widget
[5]:
from utils import browse_studies, study_viewer
browse_studies(meta, phantom='uniform', fov=12, dose=100, recon='fbp')
[6]:
study_viewer(meta)
Apply a denoiser¶
The following loads a pretrained RED-CNN implementation and uses it to process the phantom test series and compare denoising performance to the FBP inputs.
[7]:
import os
import torch
from denoising.networks import RED_CNN
def read_dicom(dcm_file):
dcm = pydicom.read_file(dcm_file)
return dcm.pixel_array + float(dcm.RescaleIntercept)
def load_model(save_path, iter_=13000, device='cpu'):
REDCNN = RED_CNN()
f = os.path.join(save_path, 'REDCNN_{}iter.ckpt'.format(iter_))
REDCNN.load_state_dict(torch.load(f, map_location=device))
return REDCNN
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
denoising_model = load_model('denoising/models/redcnn', device=device)
studyid is a useful tag for grouping all of the repeats or slices of the same phantom under different conditions, thus all of the files under a single studyid can be loaded into a volume for easier analysis
[8]:
meta.studyid.unique()
[8]:
array([64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80,
81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95])
[9]:
vol = np.array([read_dicom(o) for o in meta[meta['studyid'] == 64].file])
vol.shape
[9]:
(200, 512, 512)
After loading the model on to your device try run a small test prediction to make sure inference is working. A default batch size of 16 is given, which is how many images are processed at once by the device. If you receive errors like the following:
OutOfMemoryError: CUDA out of memory. Tried to allocate 2.82 GiB. GPU
Try reducing the batch size. For more details, see the pytorch documentation
[10]:
denoising_model.to(device)
batch_size = 16 #play around with an inference batch size that fits on your gpu
if device == torch.device('cpu'):
batch_size = 1
denoised = denoising_model.predict(vol[:, None], device=device, batch_size=batch_size)
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:07<00:00, 1.76it/s]
You could just apply the denoiser to each row individually, that would not be an efficient use of the gpu which work well with mini batches (if using a gpu, if using cpu it shouldn’t matter), this is another benefit of grouping by studyid and loading as a volume rather than single slices.
The following cell groups volumes by studyid for more efficient processing and adds their filenames and associated metadata to a new metadata dataframe called results
[11]:
rows = []
count = 0
studyids = meta[(meta['Dose [%]'] == 25)].studyid.unique()
for study in studyids:
print(f'denoising batch: {count}/{len(studyids)}')
vol = np.array([read_dicom(o) for o in meta[meta['studyid'] == study].file])
denoised = denoising_model.predict(vol[:, None], device=device, batch_size=batch_size) # replace with your own model here <--
# save result
slice_idx = 0
for idx, row in meta[meta['studyid'] == study].iterrows():
rows.append(pd.DataFrame(row).T)
new_row = row.copy()
dcm = pydicom.read_file(row.file)
new_row.recon = 'RED-CNN'
dcm.ConvolutionKernel = new_row.recon
dcm.PixelData = denoised[slice_idx].astype('int16') - int(dcm.RescaleIntercept)
slice_idx += 1
save_file = Path(str(row.file).replace('fbp', new_row.recon))
save_file.parent.mkdir(exist_ok=True, parents=True)
pydicom.write_file(save_file, dcm)
new_row.file = save_file
rows.append(pd.DataFrame(new_row).T)
count += 1
results = pd.concat(rows, ignore_index=True)
denoising batch: 0/8
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:06<00:00, 1.99it/s]
denoising batch: 1/8
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:06<00:00, 1.99it/s]
denoising batch: 2/8
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:06<00:00, 1.98it/s]
denoising batch: 3/8
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:06<00:00, 1.98it/s]
denoising batch: 4/8
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:06<00:00, 1.98it/s]
denoising batch: 5/8
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:06<00:00, 1.98it/s]
denoising batch: 6/8
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:06<00:00, 1.98it/s]
denoising batch: 7/8
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:06<00:00, 1.98it/s]
[12]:
results.head()
[12]:
| Name | effective diameter [cm] | age [year] | pediatric subgroup | phantom | scanner | Dose [%] | recon | kernel | FOV [cm] | file | patientid | studyid | series | repeat | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 11.2 cm uniform | 11.2 | 0.083333 | newborn | uniform | Siemens Somatom Definition | 25.0 | fbp | D45 | 12.0 | /home/brandon.nelson/Dev/Regulatory_Science_To... | 16.0 | 64 | simulation | 0 |
| 1 | 11.2 cm uniform | 11.2 | 0.083333 | newborn | uniform | Siemens Somatom Definition | 25.0 | RED-CNN | D45 | 12.0 | /home/brandon.nelson/Dev/Regulatory_Science_To... | 16.0 | 64 | simulation | 0 |
| 2 | 11.2 cm uniform | 11.2 | 0.083333 | newborn | uniform | Siemens Somatom Definition | 25.0 | fbp | D45 | 12.0 | /home/brandon.nelson/Dev/Regulatory_Science_To... | 16.0 | 64 | simulation | 1 |
| 3 | 11.2 cm uniform | 11.2 | 0.083333 | newborn | uniform | Siemens Somatom Definition | 25.0 | RED-CNN | D45 | 12.0 | /home/brandon.nelson/Dev/Regulatory_Science_To... | 16.0 | 64 | simulation | 1 |
| 4 | 11.2 cm uniform | 11.2 | 0.083333 | newborn | uniform | Siemens Somatom Definition | 25.0 | fbp | D45 | 12.0 | /home/brandon.nelson/Dev/Regulatory_Science_To... | 16.0 | 64 | simulation | 2 |
Visualizing the Results¶
We can use the results csv similar to meta to visualize the new image series which include the RED-CNN processed results
[13]:
browse_studies(results, phantom='uniform', fov=12, dose=25, recon='RED-CNN')
[14]:
study_viewer(results)
[15]:
from utils import make_montage
make_montage(results, roi_diameter=0.4, fovs=[12, 24], wwwl=(150, 0))

Assessing Noise Reduction¶
[16]:
from utils import measure_roi_std
%timeit measure_roi_std(results.file.iloc[1])
31.1 ms ± 155 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
This takes about 1-2 min to make all of the noise measurements across 3200 images
[17]:
results['noise std [HU]'] = results.file.apply(measure_roi_std)
[18]:
import seaborn as sns
sns.lineplot(data=results, x='FOV [cm]', y='noise std [HU]', hue='recon')
[18]:
<Axes: xlabel='FOV [cm]', ylabel='noise std [HU]'>
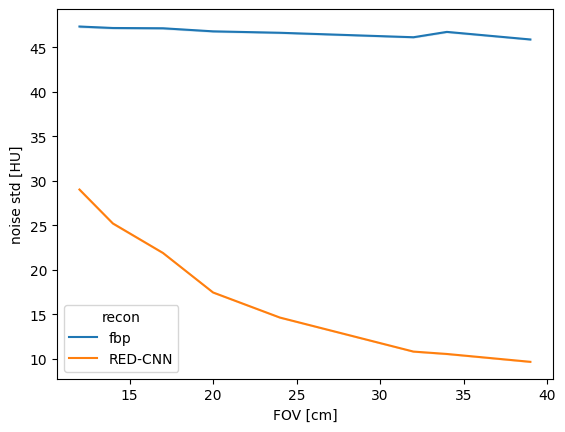
The RED-CNN model we evaluated was trained on an adult dataset of large fields of view (FOV) thus the above results show the lowest noise levels in the larger FOVs most similar to the training set. We can calculate this as a noise reduction as described previously
To get the following curve of noise reduction performance as a function of FOV.
[19]:
from utils import calculate_noise_reduction
[20]:
results = calculate_noise_reduction(results)
[21]:
sns.lineplot(data=results, x='FOV [cm]', y='noise std [HU] reduction [%]', hue='recon')
[21]:
<Axes: xlabel='FOV [cm]', ylabel='noise std [HU] reduction [%]'>
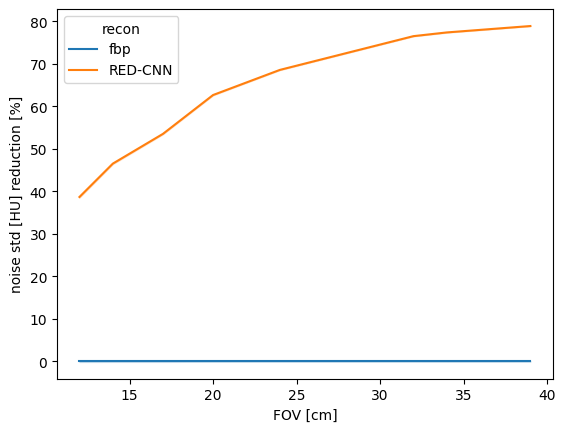
Keep in mind that abdominal imaging protocols typically use body fitting FOVs, thus for smaller patients including pediatric patients, this poorer performance in small FOVs translates to poorer performance in pediatric patients.
To this end we can rebin our results based on the pediatric subgroups define previously, here they are again plotted for comparison:
[22]:
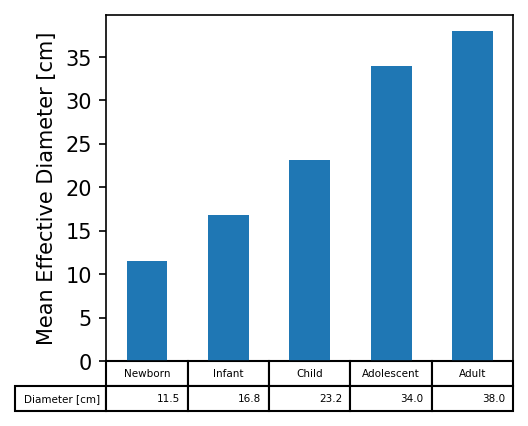
df = pd.DataFrame({'Subgroup': ['Newborn', 'Infant', 'Child', 'Adolescent', 'Adult'],
'Diameter [cm]':[11.5, 16.8, 23.2, 34, 38],
'Age [yrs]': [0, 2, 12, 21, 38]})
f, ax=plt.subplots(figsize=(3.5,3), dpi=150)
df.plot.bar(ax=ax, x='Subgroup',y='Diameter [cm]', table=True, legend=False)
ax.get_xaxis().set_visible(False)
ax.set_ylabel('Mean Effective Diameter [cm]')
[22]:
Text(0, 0.5, 'Mean Effective Diameter [cm]')
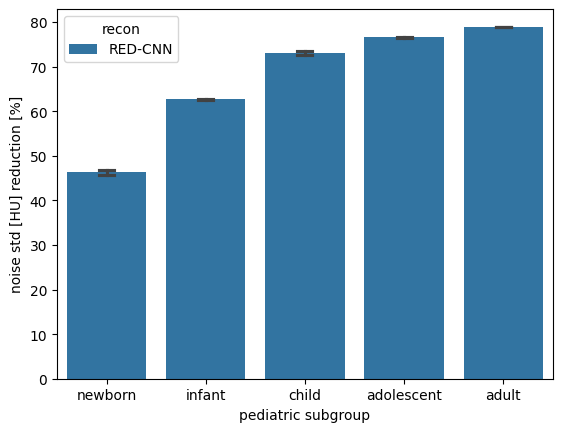
Below we can compare noise reduction performance as a function of pediatric subgroup following the binning of patient size into these subgroups and see that performance is best in adults and adolescents which better represent the adult training dataset, the Mayo Clinic Low Dose Grand Challenge Dataset
[23]:
f, ax = plt.subplots()
sns.barplot(data=results[results.recon != 'fbp'], x='pediatric subgroup', y='noise std [HU] reduction [%]', hue='recon', capsize=0.15, ax=ax)
f.savefig('../pediatric_subgroup_performance.png', dpi=300)
Conclusions¶
Noise reduction is but one of several factors to consider when assessing image quality of CT reconstructions and denoising algorithms, for more information on image quality assessments to justify dose reduction please see Vaishnav 2018. For a review of unique considerations for dose reduction with AI reconstruction and denoising please see Brady 2023.
This concludes our worked examples. Next you can refer to the API guide for more detailed function documentation or consider contributing the package.
Further Steps
These notebooks have provided simple examples for generating CT datasets representative of pediatric-sized patients with flexibility to simulate a range of x-ray dose and system parameters. Next you are encouraged to explore other tools for assessing task-based image quality using the Low Contrast Detectability for CT Toolbox which is compatible with the MITA-LCD images made available in pediatricIQphantoms